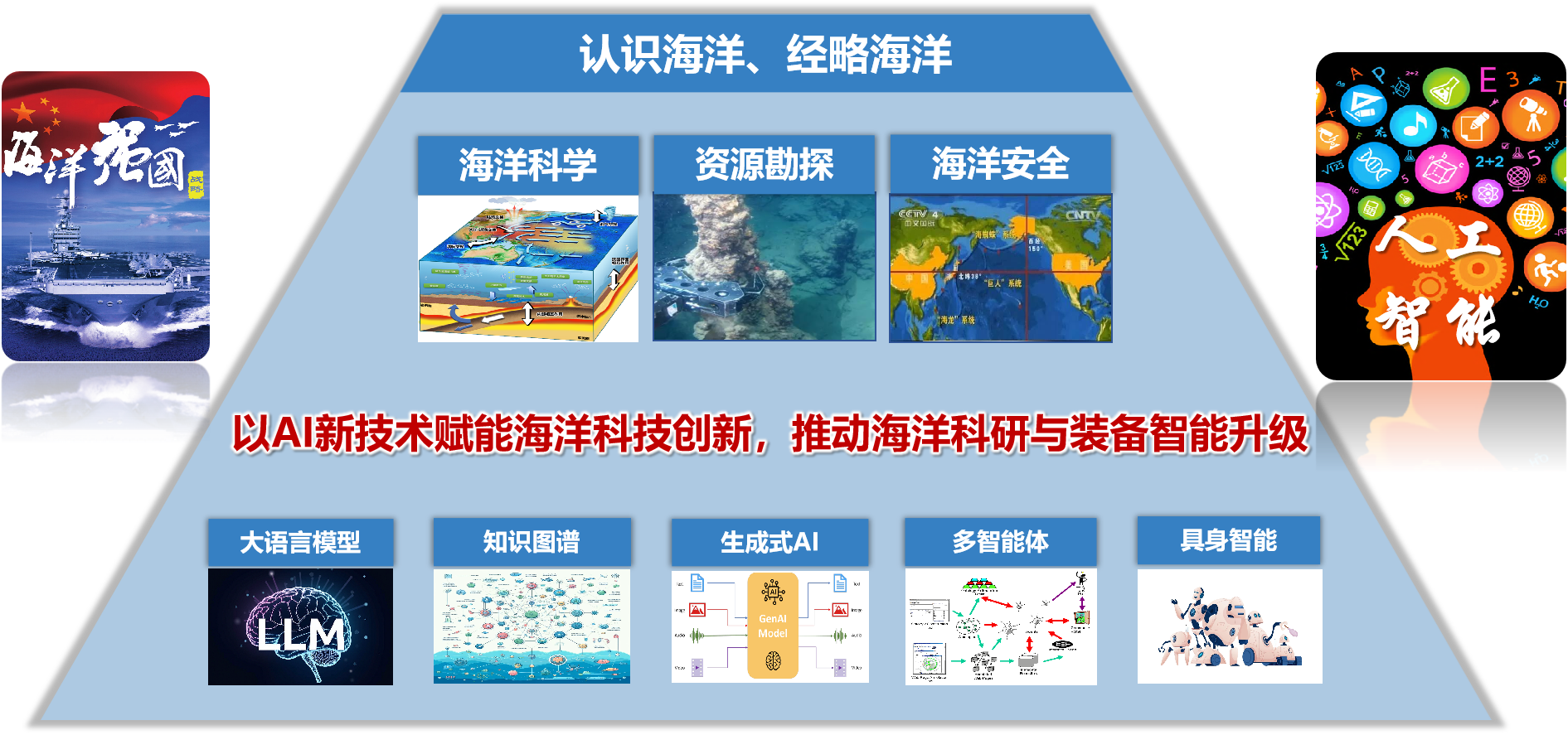
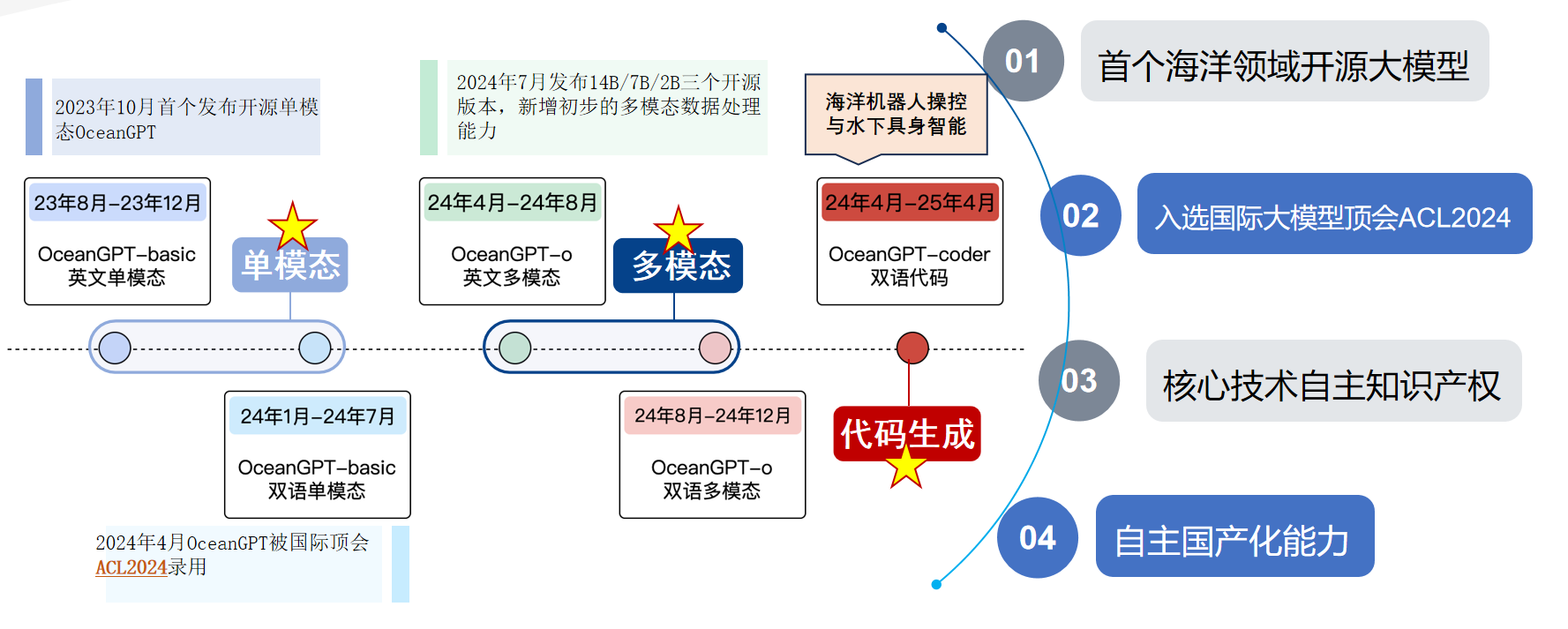
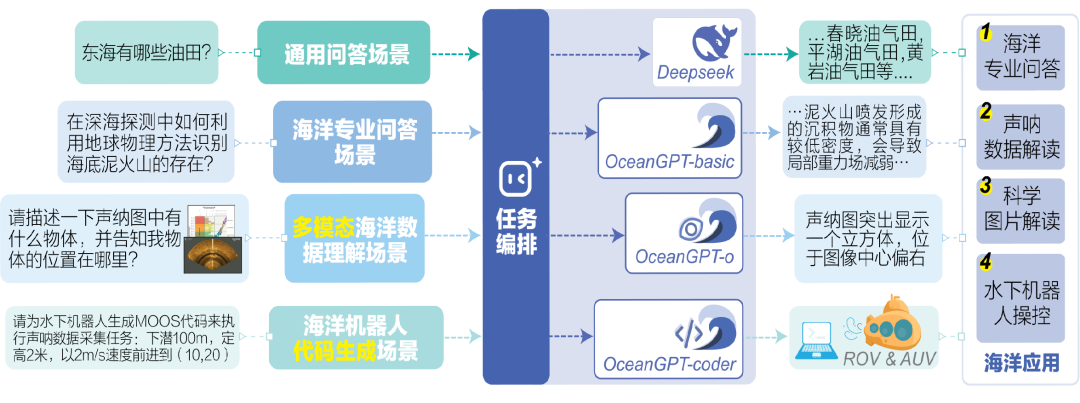
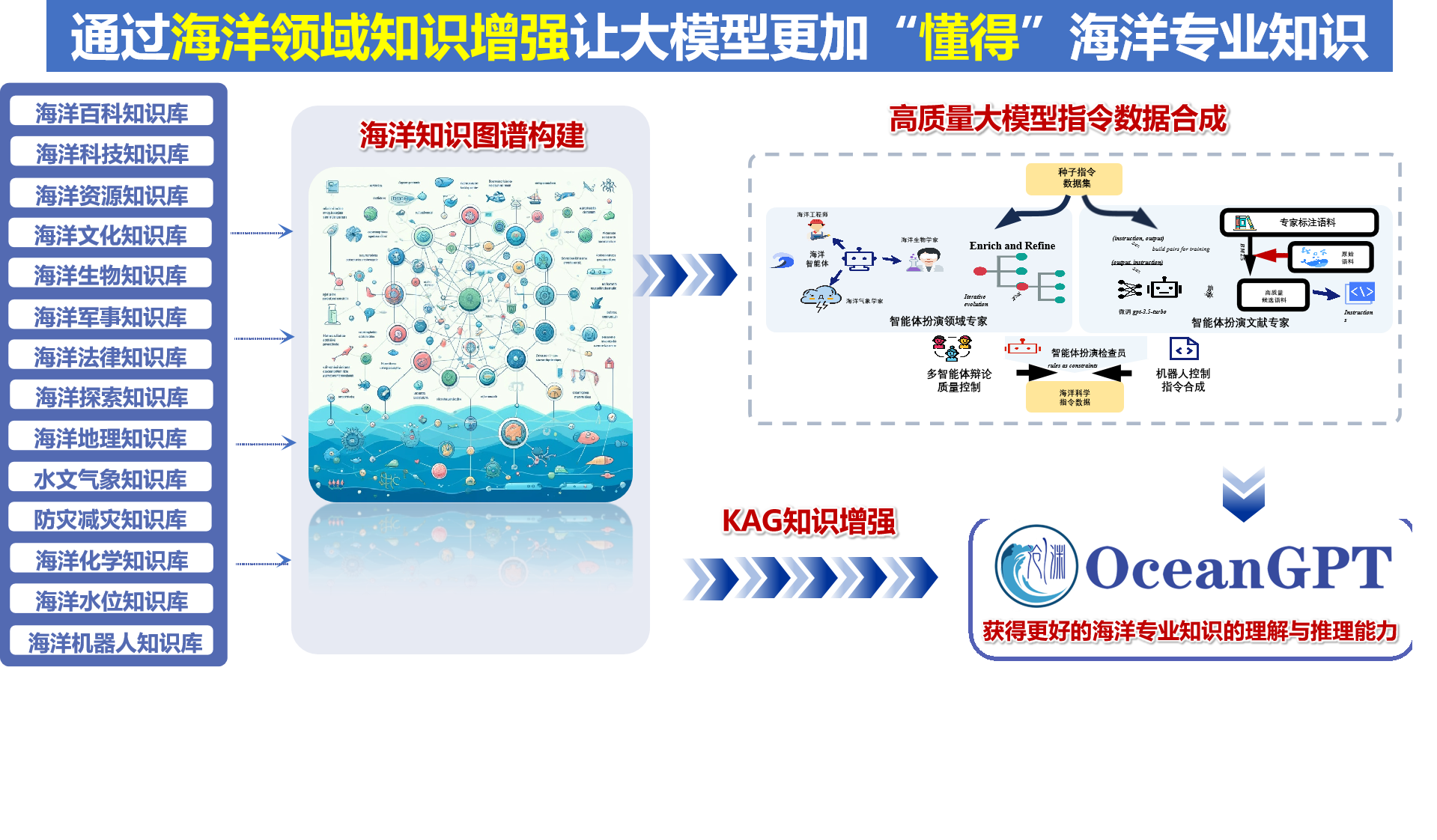
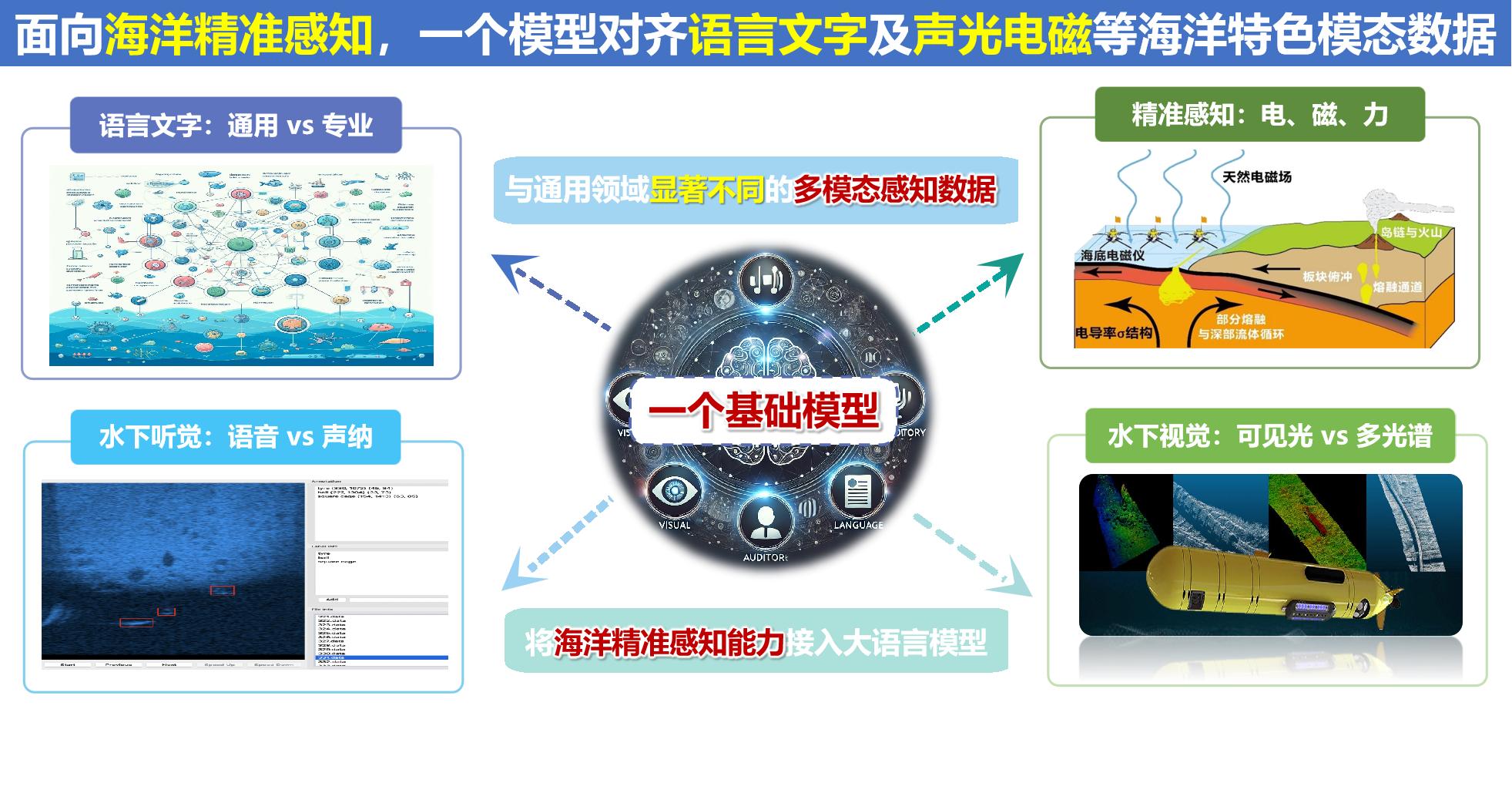
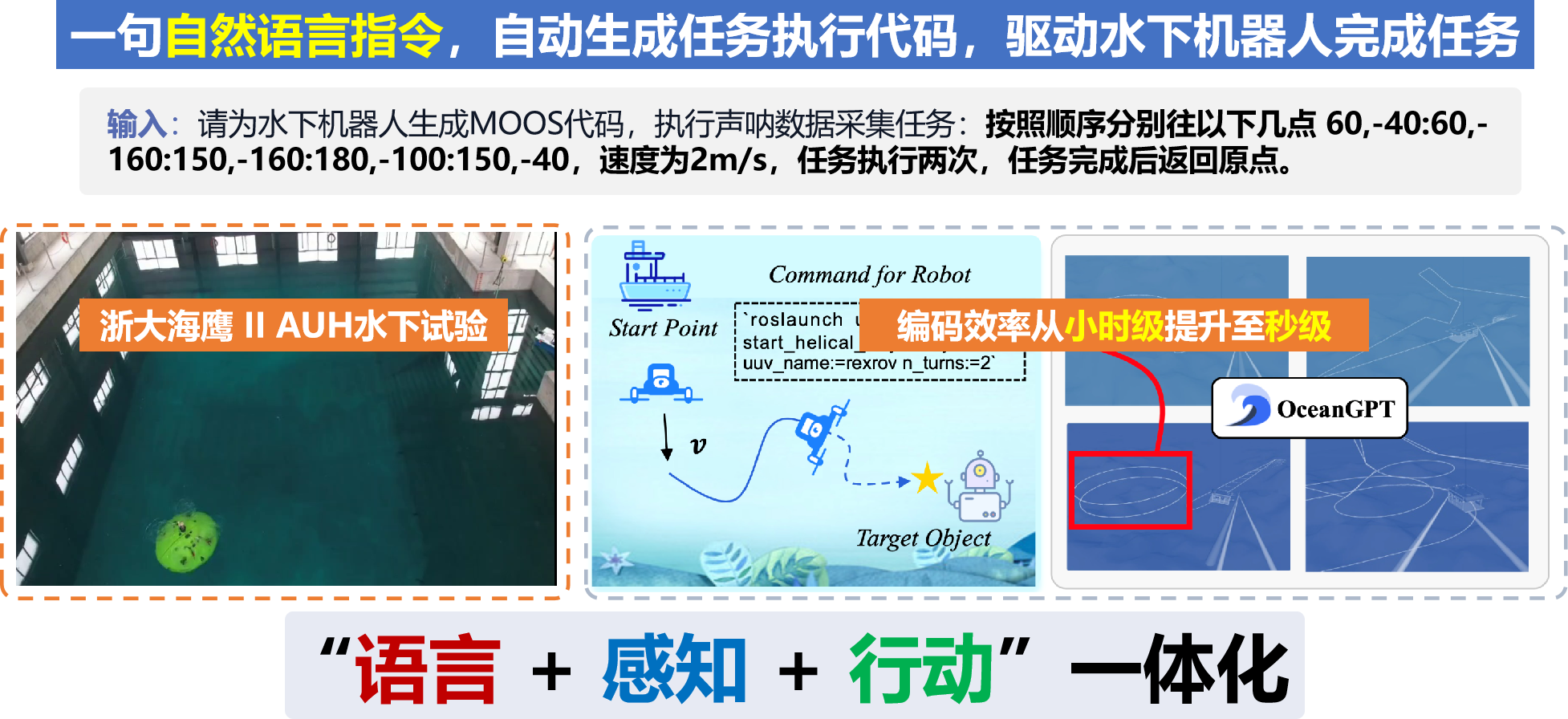
了解更多 Background 研制背景 OceanGPT·沧渊 是面向海洋科学与工程任务的专有领域大语言模型,由海洋精准感知技术全国重点实验室(浙江大学)牵头,联合计算机科学、海洋科学与机器人技术等多学科交叉团队共同研制。海洋覆盖地球表面积约71%,不仅蕴藏着丰富的自然资源,更承载着海洋强国重大战略需求。沧渊致力于融合大语言模型、知识图谱、生成式AI与具身智能等前沿AI技术,推动通用人工智能技术在海洋领域的融合创新与深度应用。 Timeline 研制时间线 沧渊研制始于2023年,是首个专注海洋领域的大语言模型,并入选国际大模型领域顶会ACL2024。随后持续迭代更新,于2025年发布升级版 OceanGPT 2.0 。沧渊秉持开源开放理念促进海洋大模型技术的演进与共享。 Model Architecture 模型体系 最新版本的OceanGPT采用混合专家架构,由多个功能子模型组成,其中,OceanGPT-basic:用于海洋基础专业知识的理解与问答,让大模型 “懂得” 海洋知识;OceanGPT-omni:定位于海洋特色多模态数据的自然语言解读,让大模型理解 “听得见、看得懂” 的海洋数据;OceanGPT-coder:用于海洋机器人操控代码生成,为水下装备装上大模型 “AI大脑” ;OceanGPT还集成了 DeepSeek 等通用大模型能力,通过“通专结合”的方式,有效融合通用语言理解能力与海洋领域专业知识,构建更全面的海洋智能模型体系。 OceanGPT-basic 领域知识增强的海洋专业问答 OceanGPT-basic 面向海洋认知场景,通过构建海洋知识图谱,结合图谱引导的指令合成与模型微调方法,并引入 KAG(Knowledge-Augmented Generation)知识增强机制,探索提升模型对海洋专业知识的理解与推理能力。初步实验结果显示,OceanGPT-basic在相关任务中相较通用大语言模型,不仅具备更好的海洋专业知识的理解与推理能力,还有效控制了模型的幻觉错误输出。 OceanGPT-Omini 海洋多模态数据理解 OceanGPT-Omni 面向海洋感知场景,旨在探索构建统一的基座模型,以实现自然语言与海洋多模态数据(如声纳、光学、电磁等)的融合与对齐。当前,OceanGPT 初步具备了对声纳图像的自然语言解析能力,能够对输入的海底声纳数据进行分析,并生成相应的语义化描述。另一方面,模型也在多种海洋专业图表的自然语言理解与分析任务中展现出潜力,初步验证了其在海洋多模态感知理解方面的可行性。 OceanGPT-coder 海洋机器人操控与水下具身智能 OceanGPT-Coder 面向海洋机器人操控与水下具身智能场景,探索自然语言到机器人控制指令的自动生成能力。该模型支持根据一句自然语言指令自动生成相应的机器人操控代码,并完成任务的下发、部署与执行流程。目前,该能力已在浙江大学“海鹰”系列水下机器人平台上进行了初步验证。实测结果表明,OceanGPT 可将原本需人工编写的控制代码生成时间从“小时级”缩短至“秒级”。此外,OceanGPT还集成MCP大模型协议,用于支持机器人系统的操控。未来,OceanGPT还可作为端侧大模型部署于海洋机器人本体,利用端侧模型的本地推理能力,进一步提升水下装备的自主作业水平与任务响应效率。 开源开放 助力海洋大模型交流合作 自首版起,OceanGPT 始终秉持开源开放理念,以助力海洋大模型的科研交流与协同创新。OceanGPT2.0继续开放十万级海洋专业指令数据集,并新增开源的多模态大模型以及海洋机器人代码大模型。相关开放资源均可通过 OceanGPT 官网获取。